5. Trees
In this chapter, we explore a common data structure: trees, and related algorithms. We will start with a simple tree, understand the concept, and then learn about a specialized tree: binary tree. After that, we will explore a specialized binary tree: binary search tree. Further, we will also learn about the balanced binary tree.
Trees are very common plants in our lives, as shown in the diagram.

A tree has a root with multiple branches, each branch having leaves or other small branches. In fact, many data structures in our everyday lives look like a tree. For example, the pedigree chart, a.k.a., a family tree, grows from a pair of ancestors. We also use the phrase "branching out" to describe this process. Another example is file structure, where a folder may contain some files and other folders, just like leaves and branches. Mathematical expressions can also be represented as a tree, where each node is an operator, and each leaf is a number, with operators closer to the root being computed later.
Trees
In data structures, a tree is a finite collection of nodes that have a hierarchical relationship. Each node is a structure that stores data. It is common to describe this hierarch using family relationships, like parents, children, descendants and ancestors. Sometimes, we say there is a parent-child relationship between adjacent nodes, calling them parent nodes and child nodes. A node's descendants are all the nodes that stem from a node, while a node’s ancestors are all the nodes that it stems from.
If a tree is not empty, it should have exactly one root node, which has only child nodes and no parent nodes. All nodes except the root node should have exact one parent node. Nodes without child nodes, which are the outermost layer of nodes, are called leaf nodes, akin to the leaves of a tree. Additionally, no node can be its own descendant, meaning cycles cannot exist within the tree.

In a tree, an edge refers to a pair of nodes
The example below is not a tree.

Each red mark violates the requirements of a tree. In the upper right, there's another root node without a parent node, implying two root nodes in a tree, which is not allowed. At the bottom, the left leaf node has an extra arrow pointing to the root node, implying it's the parent node of the root, violating the structure requirements. And the right leaf node has two parent nodes, which also doesn't comply with the requirements.
It's common to place the root node at the top, with child nodes arranged below their parent nodes. We have some terms related to trees. Firstly, the depth of a node corresponds to the length of the path from the root node down to that node. In other words, the number of edges traversed when going from the root node downwards. Therefore, the depth of the root is
Having discussed the logical structure of a tree, let's now consider its storage structure. While the logical structure defines the relationships between data, the storage structure defines the specific representation of data. We'll use a binary tree as an example, where each node has at most two children. Here, we'll represent the tree using a list of tuples. Each tuple defines a parent-child relationship, such as (0, 1), indicating that node
Another way is to use algebraic data structures we have talked about previously:
Node(0,
Node(1,
Leaf(3),
Empty),
Leaf(2))
We define several cases using an enumeration type: Node represents a regular tree node with its own number and two subtrees, Leaf represents a tree with only one node, i.e., a leaf node, having only its own number, and Empty represents an empty tree. With this representation, we can define a tree structure similar to before. Of course, this is just one possible implementation.
The final approach is a list where each level's structure is arranged consecutively from left to right:

For example, the root node is placed at the beginning of the list, followed by nodes of the second level from left to right, then nodes of the third level from left to right, and so on. Thus, node
We can see that all three methods define the same tree, but their storage structures are quite different. Hence, we can conclude that the logical structure of data is independent of its storage structure.
Finally, the tree data structure has many derivatives. For example, a segment tree stores intervals and corresponding data, making it suitable for one-dimensional queries. Binary trees are a special type where each node has at most two branches, namely the left subtree and the right subtree. B-trees are suitable for sequential access, facilitating the storage of data on disks. KD-trees and R-trees, which are derivatives of binary trees and B-trees respectively, are suitable for storing spatial data structures. Apart from these, there are many other tree structures.
Binary Trees
A binary tree is either empty or consist of nodes that have at most two subtrees: a left subtree and a right subtree. For example, both subtrees of a leaf node are empty. Here, we adopt a definition based on recursive enumeration types, with default data storage being integers.
enum IntTree {
Node(Int, IntTree, IntTree) // data, left subtree, right subtree
Empty
}
The first algorithm we will discuss is binary tree traversal (or search). Tree traversal refers to the process of visiting all nodes of a tree in a certain order without repetition. Typically, there are two methods of traversal: depth-first and breadth-first. Depth-first traversal always visits one subtree before the other. During the traversal of a subtree, it recursively visits one of its subtrees. Thus, it always reaches the deepest nodes first before returning. For example,

In the diagram, we first visit the left subtree, then the left subtree again, leading to the visit of
Depth-first traversal usually involves three variations: preorder traversal, inorder traversal, and postorder traversal. The difference lies in when the root node is visited while traversing the entire tree. For example, in preorder traversal, the root node is visited first, followed by the left subtree, and then the right subtree. Taking the tree we just saw as an example, this means we start with [0, 1, 2, 3, 4, 5].
Let's take a look at the specific implementation of these two traversals in terms of finding a specific value in the tree's nodes. Firstly, let's consider depth-first traversal.
fn dfs_search(target: Int, tree: IntTree) -> Bool {
match tree { // check the visited tree
Empty => false // empty tree implies we are getting deepest
Node(value, left, right) => // otherwise, search in subtrees
value == target || dfs_search(target, left) || dfs_search(target, right)
}
}
As we introduced earlier, this is a traversal based on structural recursion. We first handle the base case, i.e., when the tree is empty, as shown in the third line. In this case, we haven't found the value we're looking for, so we return false. Then, we handle the recursive case. For a node, we check if its value is the desired result, as shown in line 5. If we find it, the result is true. Otherwise, we continue to traverse the left and right subtrees alternately, if either we find it in left subtree or right subtree will the result be true. In the current binary tree, we need to traverse both the left and right subtrees to find the given value. The binary search tree introduced later will optimize this process. The only differences between preorder, inorder, and postorder searches is the order of operations on the current node, the left subtree search, and the right subtree search.
Queues
Now let's continue with breadth-first traversal.

As mentioned earlier, breadth-first traversal involves visiting each subtree layer by layer. In this case, to be able to record all the trees we are going to visit, we need a brand-new data structure: the queue.

A queue is a first-in-first-out (FIFO) data structure. Each time, we dequeue a tree from the queue and check whether its node value is the one we're searching for. If not, we enqueue its non-empty subtrees from left to right and continue the computation until the queue is empty.
Let's take a closer look. Just like lining up in real life, the person who enters the line first gets served first, so it's important to maintain the order of arrival. The insertion and deletion of data follow the same order, as shown in the diagram. We've added numbers from
The queue we're using here is defined by the following interface:
fn empty[T]() -> Queue[T] // construct an empty queue
fn enqueue[T](q: Queue[T], x: T) -> Queue[T] // add element to the tail
// attempt to dequeue an element, return None if the queue is empty
fn pop[T](q: Queue[T]) -> (Option[T], Queue[T])
empty: construct an empty queue; enqueue: add an element to the queue, i.e., add it to the tail; pop: attempt to dequeue an element and return the remaining queue. If the queue is already empty, the returned value will be None along with an empty queue. For example,
let q = enqueue(enqueue(empty(), 1), 2)
let (head, tail) = pop(q)
assert(head == Some(1))
assert(tail == enqueue(empty(), 2))
We've added Some(1), and what's left should be equivalent to adding
Let's return to the implementation of our breadth-first traversal.
fn bfs_search(target: Int, queue: Queue[IntTree]) -> Bool {
match pop(queue) {
(None, _) => false // If the queue is empty, end the search
(Some(head), tail) => match head { // If the queue is not empty, operate on the extracted tree
Empty => bfs_search(target, tail) // If the tree is empty, operate on the remaining queue
Node(value, left, right) =>
if value == target { true } else {
// Otherwise, operate on the root node and add the subtrees to the queue
bfs_search(target, enqueue(enqueue(tail, left), right))
}
}
}
}
If we want to search for a specific value in the tree's nodes, we need to maintain a queue containing trees, as indicated by the parameters. Then, we check whether the current queue is empty. By performing a pop operation and pattern matching on the head of the queue, if it's empty, we've completed all the searches without finding the value, so we return false. If the queue still has elements, we operate on this tree. If the tree is empty, we directly operate on the remaining queue; if the tree is not empty, as before, we check if the current node is the value we're looking for. If it is, we return true; otherwise, we enqueue the left and right subtrees left and right into the queue and continue searching the queue.
So far, we've concluded our introduction to tree traversal. However, we may notice that this type of search doesn't seem very efficient because every subtree may contain the value we're looking for. Is there a way to reduce the number of searches? The answer lies in the binary search tree, which we'll introduce next.
Binary Search Trees
Previously, we mentioned that searching for elements in a binary tree might require traversing the entire tree. For example, in the diagram below, we attempt to find the element

For the left binary tree, we have to search the entire tree, ultimately concluding that
To facilitate searching, we impose a rule on the arrangement of data in the tree based on the binary tree: from left to right, the data is arranged in ascending order. This gives rise to the binary search tree. According to the rule, all data in the left subtree should be less than the node's data, and the node's data should be less than the data in the right subtree, as shown in the diagram on the right.
We notice that if we perform an inorder traversal, we can traverse the sorted data from smallest to largest. Searching on a binary search tree is very simple: determine whether the current value is less than, equal to, or greater than the value we are looking for, then we know which subtree should be searched further. In the example above, when we check if
To maintain such a tree, we need special algorithms for insertion and deletion to ensure that the modified tree still maintains its order. Let's explore these two algorithms.

For the insertion on a binary search tree, we also use structural recursion. First, we discuss the base case where the tree is empty. In this case, we simply replace the tree with a new tree containing only one node with the value we want to insert. Next, we discuss the recursive case. If a tree is non-empty, we compare the value we want to insert with the node's value. If it's less than the node, we insert the value into the left subtree and replace the left subtree with the subtree after insertion. If it's greater than the node, we replace the right subtree. For example, if we want to insert
fn insert(tree: IntTree, value: Int) -> IntTree {
match tree {
Empty => Node(value, Empty, Empty) // construct a new tree if it's empty
Node(v, left, right) => // if not empty, update one subtree by insertion
if value == v { tree } else
if value < v { Node(v, insert(left, value), right) } else
{ Node(v, left, insert(right, value)) }
}
}
Here we can see the complete insertion code. In line 3, if the original tree is empty, we reconstruct a new tree. In lines 6 and 7, if we need to update the subtree, we use the Node constructor to build a new tree based on the updated subtree.
Next, we discuss the delete operation.
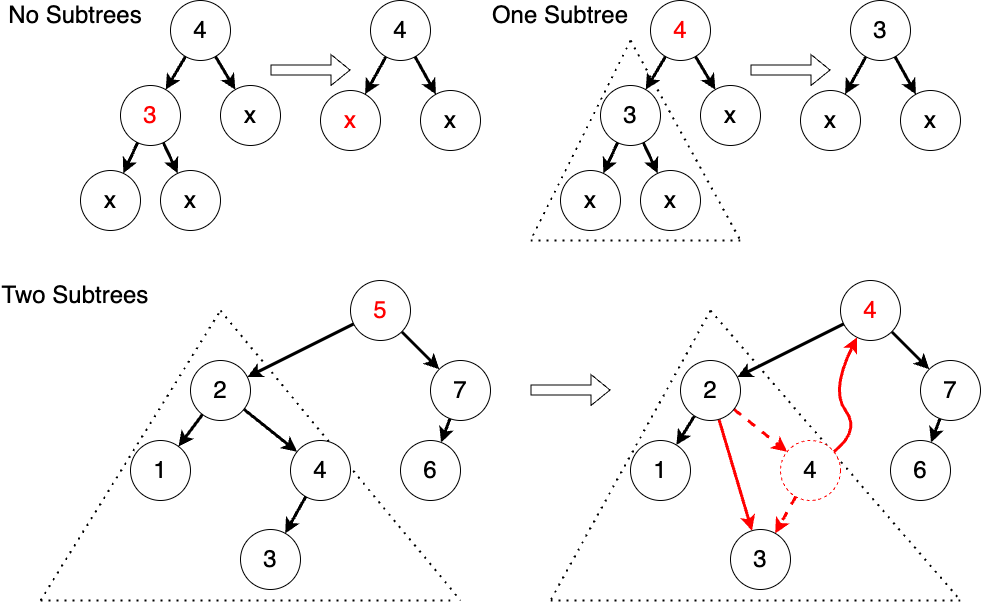
Similarly, we do it with structural recursion. If the tree is empty, it's straightforward because we don't need to do anything. If the tree is non-empty, we need to compare it with the current value and determine whether the current value needs to be deleted. If it needs to be deleted, we delete it. We'll discuss how to delete it later; if it's not the value we want to delete, we still need to compare it and find the subtree where the value might exist, then create an updated tree after deletion. The most crucial part of this process is how to delete the root node of a tree. If the tree has no subtrees or only one subtree, it's straightforward because we just need to replace it with an empty tree or the only subtree. The trickier part is when there are two subtrees. In this case, we need to find a new value to be the root node, and this value needs to be greater than all values in the left subtree and less than all values in the right subtree. There are two values that satisfy this condition: the maximum value in the left subtree and the minimum value in the right subtree. Here, we use the maximum value in the left subtree as an example. Let's take another look at the schematic diagram. If there are no subtrees, we simply replace it with an empty tree; if there's one subtree, we replace it with the subtree. If there are two subtrees, we need to set the maximum value in the left subtree as the value of the new root node and delete this value from the left subtree. The good news is that this value has at most one subtree, so the operation is relatively simple.
fn remove_largest(tree: IntTree) -> (IntTree, Int) {
match tree {
Node(v, left, Empty) => (left, v)
Node(v, left, right) => {
let (newRight, value) = remove_largest(right)
(Node(v, left, newRight), value)
} }
}
fn remove(tree: IntTree, value: Int) -> IntTree {
match tree { ...
Node(root, left, right) => if root == value {
let (newLeft, newRoot) => remove_largest(left)
Node(newRoot, newLeft, right)
} else ... }
}
Here, we demonstrate part of the deletion of a binary search tree. We define a helper function to find and delete the maximum value from the left subtree. We keep traversing to the right until we reach a node with no right subtree because having no right subtree means there are no values greater than it. Based on this, we define the deletion, where when both subtrees are non-empty, we can use this helper function to obtain the new left subtree and the new root node. We omit the specific code implementation here, leaving it as an exercise for you to practice after class.
Balanced Binary Trees
Finally, we delve into the balanced binary trees. When explaining binary search trees, we mentioned that the worst-case number of searches in a binary search tree depends on the height of the tree. Insertion and deletion on a binary search tree may cause the tree to become unbalanced, meaning that one subtree's height is significantly greater than the other's. For example, if we insert elements from

We can see that for the entire tree, the height of the left subtree is
The key to maintaining balance in a binary balanced tree is that when the tree becomes unbalanced, we can rearrange the tree to regain balance. The insertion and deletion of AVL trees are similar to standard binary search trees, except that AVL trees perform adjustments after each insertion or deletion to ensure the tree remains balanced. We add a height attribute to the node definition.
enum AVLTree {
Empty
// current value, left subtree, right subtree, height
Node(Int, ~left: AVLTree, ~right: AVLTree, ~height: Int)
}
fn create(value : Int, ~left : AVLTree = Empty, ~right : AVLTree = Empty) -> AVLTree
fn height(tree: AVLTree) -> Int
Here, we used the syntax for labeled arguments, which we introduced in Chapter 3 and Chapter 4. The create function creates a new AVL tree whose both subtrees are empty by default, without explicitly maintaining its height. Since the insertion and deletion operations of AVL trees are similar to standard binary search trees, we won't go into detail here.
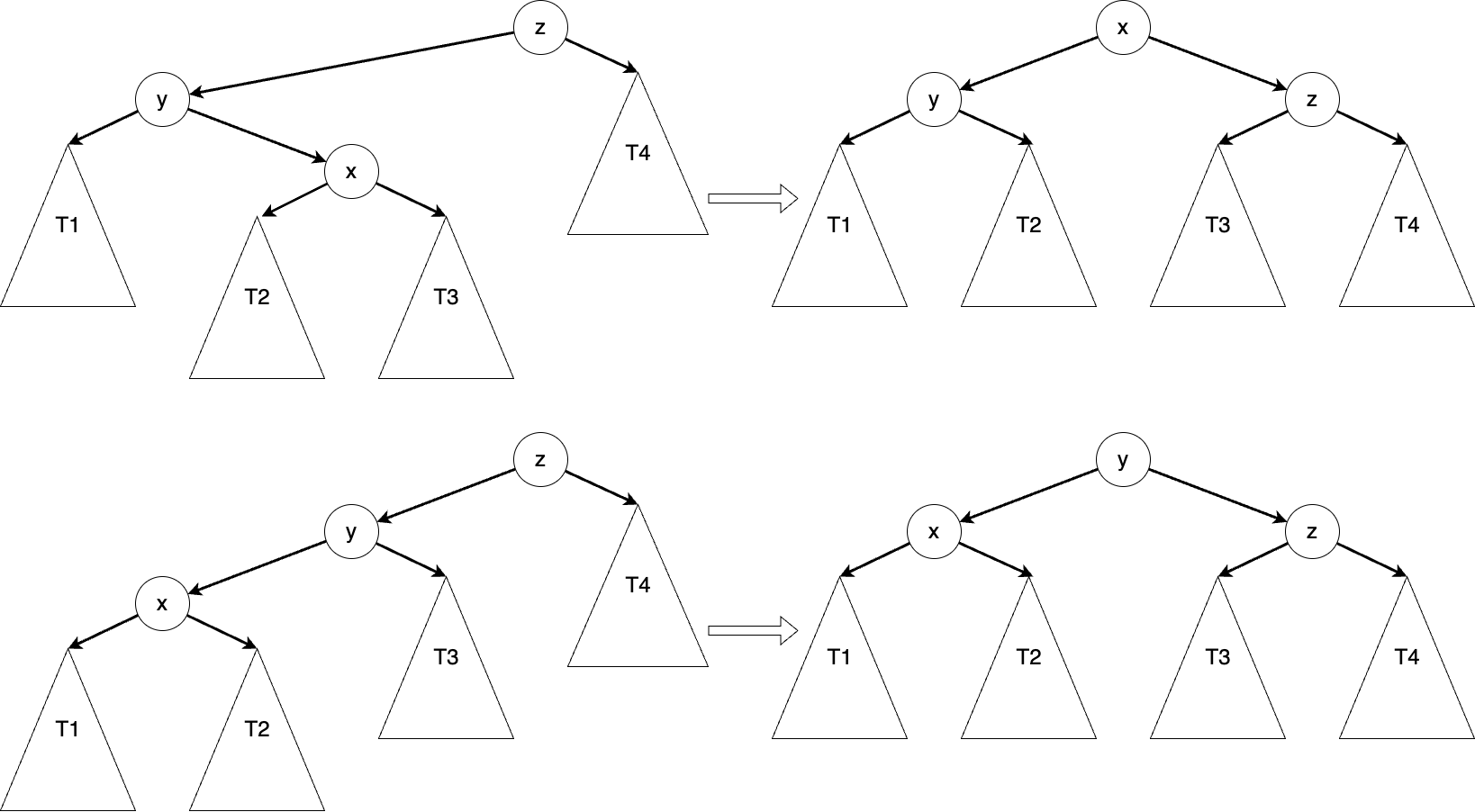
After inserting or deleting an element, we traverse back from the modified location until we find the first unbalanced position, which we call
fn balance(left: AVLTree, z: Int, right: AVLTree) -> AVLTree {
if height(left) > height(right) + 1 {
match left {
Node(y, left_l, left_r, _) =>
if height(left_l) >= height(left_r) {
create(left_l, y, create(lr, z, right)) // x is on y and z's same side
} else { match left_r {
Node(x, left_right_l, left_right_r, _) => // x is between y and z
create(create(left_l, y, left_right_l), x, create(left_right_r, z, right))
} }
}
} else { ... }
}
Here is a snippet of code for a balanced tree. You can easily complete the code once you understand what we just discussed. We first determine if a tree is unbalanced, by checking if the height difference between the two subtrees exceeds a specific value and which side is higher. After determining this, we perform a rebalancing operation. At this point, the root node we pass in is
fn add(tree: AVLTree, value: Int) -> AVLTree {
match tree {
// When encountering the pattern `Node(v, ..) as t`,
// the compiler will know that `t` must be constructed by `Node`,
// so `t.left` and `t.right` can be directly accessed within the branch.
Node(v, ..) as t => {
if value < v { balance(add(t.left, value), v, t.right) } else { ... }
}
Empty => ...
}
}
After inserting the element, we directly perform a rebalancing operation on the resulting tree.
Summary
In this chapter, we introduced the trees, including the definition of a tree and its related terminology, the definition of a binary tree, traversal algorithms, the definition of a binary search tree, its insertion and deletion operations, as well as the rebalancing operation of AVL trees, a type of balanced binary tree. For further study, please refer to:
- Introduction to Algorithms: Chapter 12 - Binary Search Trees; and
- Introduction to Algorithms: Chapter 13 - Red-Black Trees